There are many online tools, browser extensions, and desktop plugins to turn a webpage into a PDF. If you regularly use these tools, you might come across a situation when you need to convert multiple links in one go. Doing them one-by-one is a waste of time and tedious.
You can automate this task through a simple, command-line utility called Wget. With the help of a few scripts or apps and this tool, we’ll show you how to save multiple webpages into a PDF file.
Why Wget?
Wget is a free software package to download files from the web. But it’s also a perfect tool to mirror an entire webpage into your computer. Here are the reasons:
- It is non-interactive, meaning that it can work in the background and let you transfer data without requiring your presence.
- Wget understands the directory structure of the website. It can follow links in the HTML page, to create a local version of remote website. In the process, it also respects the robots.txt file.
- It can even work in slow or unstable network connections. If the server supports regetting, it’ll keep retrying until the whole file transfer to your computer.
- Wget supports proxy servers. It helps to lighten the network load, speed up retrieval process, and provide access behind the firewalls.
Installing Wget
On macOS
The quickest way to install Wget is through the Homebrew. It’s a package manager for macOS to install useful Unix utilities and apps. Check out this article on how to install macOS apps through Homebrew. Then, type in
brew install wgetYou’ll get real-time progress of installing all the tools (if any) required for Wget to run on your Mac. If you already have installed Homebrew, be sure to run brew upgrade to get the latest version of this utility.
On Windows 10
There are many versions of Wget available for Windows 10. Head to Eternally Board to download the latest 64-bit build. Put the executable file in a folder and copy it to the C: drive.

Now we’ll add Wget path to your system’s environment variable to run this tool from any directory. Navigate to Control Panel > System and click Advanced System Settings. In the window that opens, click Environment Variables.

Select Path under System variables and click Edit. Then, click on the New button located at the upper-right corner of the window. Type in C:wget and click Ok.

Open Command Prompt and type wget-h to test if everything works. In PowerShell type wget.exe -h to load the Wget help menu.

Save Your Links in a Text File
Since we’re dealing with multiple links, pasting links one-by-one is a difficult task. Thankfully, there are browser extensions to help you complete this task.
Link Klipper: It extracts all the links on a webpage as a CSV or TXT file. You can even drag a rectangular area on the webpage to selectively copy links. The file gets saved to the Download folder.

Snap Links Plus: This lets you lasso elements on a page and do things with them. Hold down the right mouse button and drag a selection rectangle around links. Press the Control key and copy your links to the clipboard.
Setting Up a Directory
Wget works like a web crawler by extracting web page assets from the HTML files, including logo, fonts, image thumbnails, CSS, and JavaScript files. It also tries to create a directory structure resembling the remote server. Create a separate directory for Wget downloads to save webpages and also to prevent clutter.
On your Mac Terminal or in a Command Prompt on Windows, enter
mkdir WgetdownThis creates a new folder in Home directory. You can name it anything you like. Next, enter
cd WgetdownChange directory. This changes the present working directory to Wgetdown.
Details of the Wget Commands
After creating the directory, we’ll use the actual Wget command
wget -E -H -k -K -p -i [Path to Your Text File]Wget uses GNU getopt to process command-line arguments. Every option has a long form along with the short ones. Long options are convenient to remember but take time to type. You may also mix different option styles. Let’s go into the details of these options:
- -E (–adjust-extension): If a file of type “app/xhtml+xml” or “text/html” gets downloaded and the URL does not end with the HTML, this option will append HTML to the filename.
- -H (–span-hosts): When you’re trying to retrieve links recursively, one does not wish to retrieve loads of unnecessary data. You want Wget to follow only specific links. This option turns on host spanning, that allows Wget recursive run to visit any host referenced by a link. For example, images served from a different host.
- -p (–page-requisites): This option download all the files that are necessary for displaying an HTML page. It includes inline images, audio, and referenced stylesheets.
- -k (–convert-links): It converts the links in the document to make them suitable for offline viewing. It includes embedded images, links to style sheets, hyperlinks to non-HTML content, and more.
- -K (–backup-converted): When converting a file, this option backs up the original version with a .orig suffix.
- -i (–input-file): Read URLs from a path to your local or external file.
Putting the Commands in Use
To demonstrate these commands in practice, consider a website manual called Writing Workflows. This manual consists of a table of contents with a link to individual chapters. The end goal is you want to create a separate PDF file of those sections.
Step 1: Open Terminal and create a new folder, as discussed above.

Step 2: Use the Link Klipper extension to save your links as a text file. Save your file to the Downloads folder.

Step 3: While you’re in the Wgetdown folder, type in
wget -E -H -k -K -p -i /Users/rahulsaigal/Downloads/links.txt
Step 4: Press Enter. Wait for the process to complete.

Step 5: Navigate to the Wgetdown folder. You’ll see the primary domain processedword.net folder with all web page assets and chapter1.html.

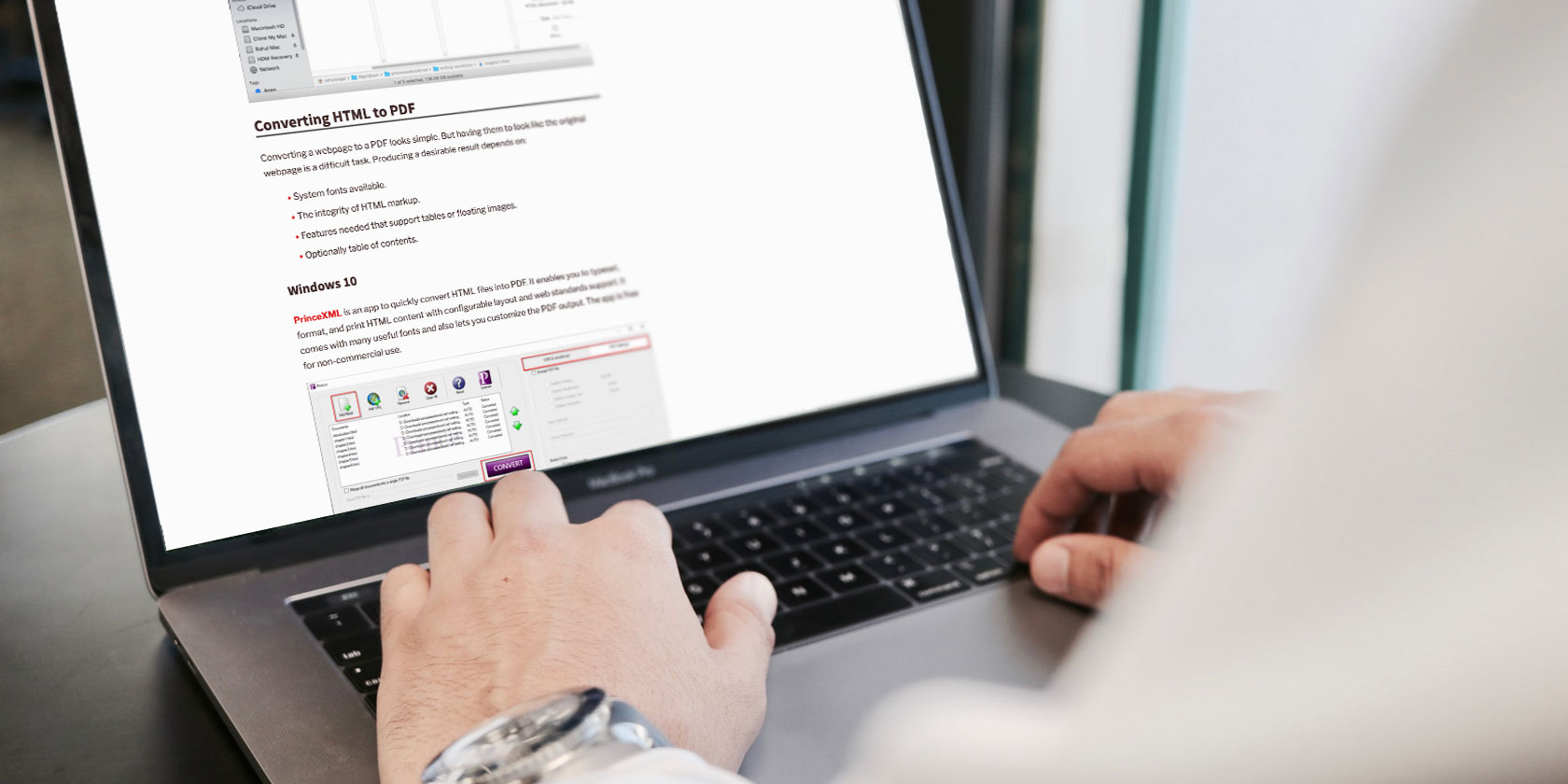
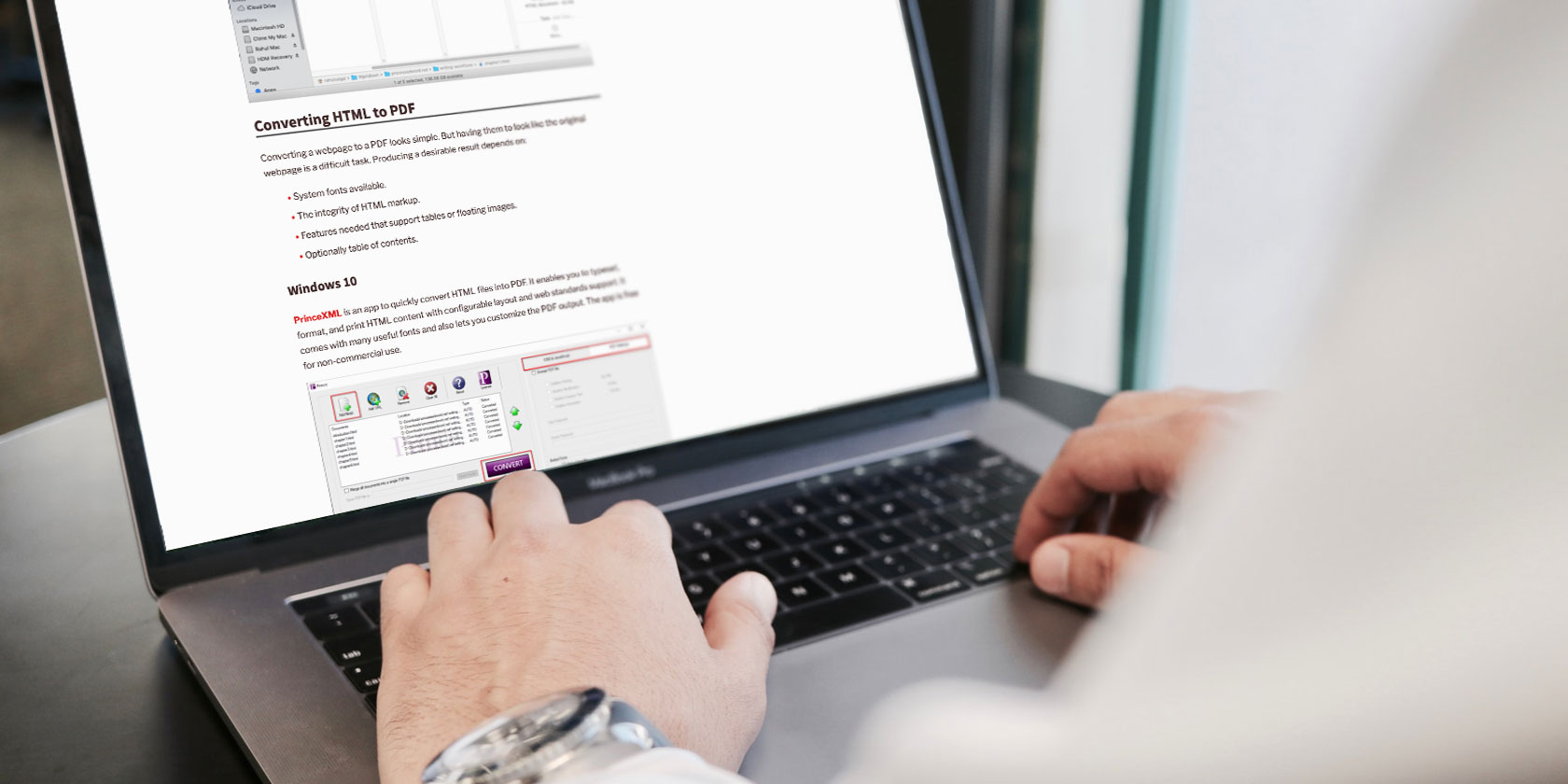
Converting HTML to PDF
Converting a webpage to a PDF looks simple. But having them to look like the original webpage is a difficult task. Producing a desirable result depends on:
- System fonts available.
- The integrity of HTML markup.
- Features needed that support tables or floating images.
- Optionally table of contents.
Windows 10
PrinceXML is an app to quickly convert HTML files into PDF. It enables you to typeset, format, and print HTML content with configurable layout and web standards support. It comes with many useful fonts and also lets you customize the PDF output. The app is free for non-commercial use.

macOS
On your Mac, you can create an Automator service to convert a batch of HTML files into PDFs. Open Automator and create a Quick Action document. Set the service option to receive files or folders from Finder. Next drag in Run Shell Script and set Pass input option to as arguments. Then, paste this script in the body
for theFileToProcess in "$ @" do cupsfilter "$ theFileToProcess" > "$ {theFileToProcess%.*}.pdf" doneSave the file as HTML2PDF.

Now select all the HTML files in Finder. Right-click and choose Services > HTML2PDF. Wait for a few moments to convert all your files.

Ways to Convert Single Webpage into PDF
At first sight, the steps involved in converting multiple webpages into PDF looks complicated. But once you understand the steps and process, it’ll save time in the long run. You don’t have to spend money on any web subscriptions or expensive PDF converters.
If you’re looking for ways to turn a single webpage into PDF, read this piece on how to convert webpages into PDF.
Read the full article: How to Convert Multiple Webpages Into PDFs With Wget

